
ES
中间件ES(Elastic Search)

分词操作个人理解就是在做一个表来记录term和id的关系,可能会再存储一大段信息的时候会出现一定时间的延迟创建。
优化,先按字典序排序通过二分查找来找到词项。

Term dictionary过大所以不可能会放在内存里面,但是放在磁盘里面,搜索过程又会很慢。
优化
每一个词项会有相似的地方,那么把这些相似的地方拎出来进行复用,然后就能构建出一个目录树的结构,进行偏移量的辅助指向后续拼接的term。感觉有一点像计算机的存储方式结构。
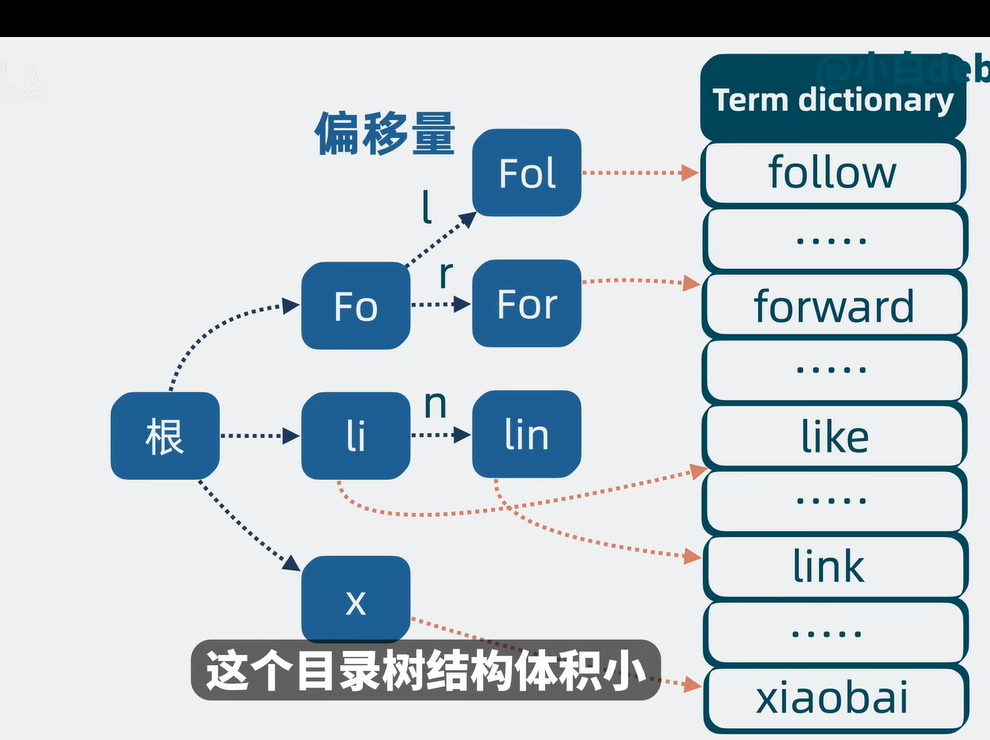
term index(上面优化出来的目录树结构就是index)
通过index能够找到term的大概位置,通过少量的检索找到target.
Stored Fields
存放完整文档内容,行式存储结构
Doc Values
空间换时间,把形同的字段归纳在一起,列式存储结构。
segment
具备完整搜索功能的最小单元

Lucene
- 因为segment结构特殊,若是有数据写入,则需要刷新整个segment架构的所有信息。这样读取和写入若是并行的话,性能会大量降低。因此为了规避这个风险,所以不允许新的信息写入segment,所以只能生成新的segment,那么问题就来了,我怎么知道我要取的信息在哪个Segment里面呢。
- 为了解决上面的问题,所以需要程序进行并发读取,但是随着数据量过大,并发读取的任务就会变得很重。导致文件句柄耗尽。
- 为了解决句柄消耗严重的问题引出了段合并,segment merging,这个功能就是解决了segment过多的问题,是用来把小一点的segment合并成一个大的segment。和前面的不允许新的信息写入是不冲突的。
到这里都还没有解释到lucene,综合上面多个segment组成的一个单机文本检索库,这个就是一个有名的开源基础搜索库Lucene
Lucene高性能
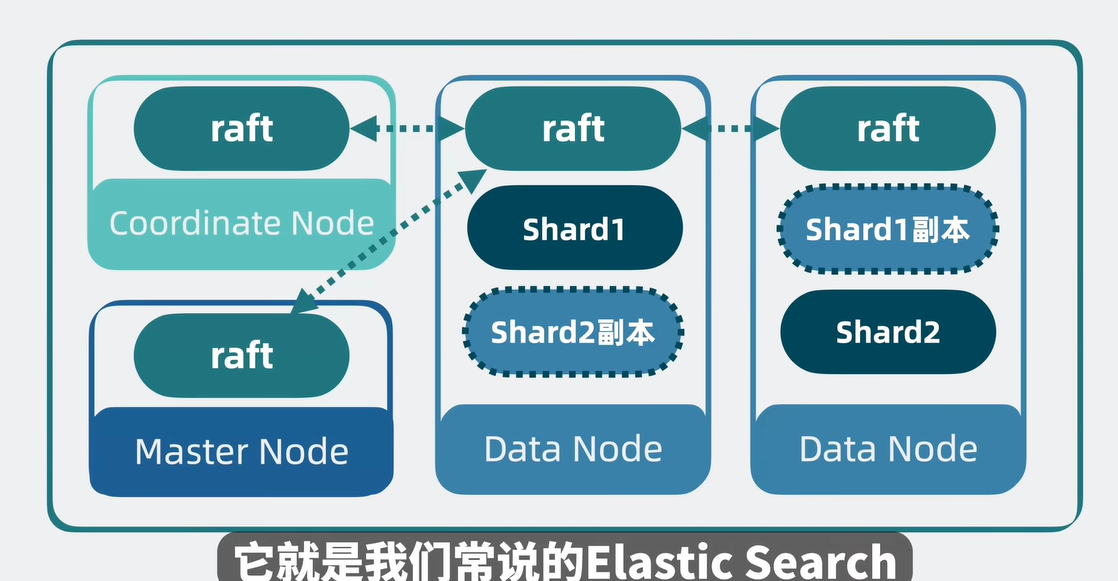
其实和kafka的原理基本都是一样的,为了用多用户并发读取,所以就回用topic来继续区分,在Lucene中我们叫index name,继续topic里面可能存在的问题,所以会把这个topic区分片,形成partition,我们这里叫作shard。其实每一个shard就是一个独立Lucene库。
Lucene高扩展
- 为了避免多个分片shard过多导致性能过高,存在宕机隐患。我们可以把它们不定的shard放在不同的node里面,来防止性能过高。
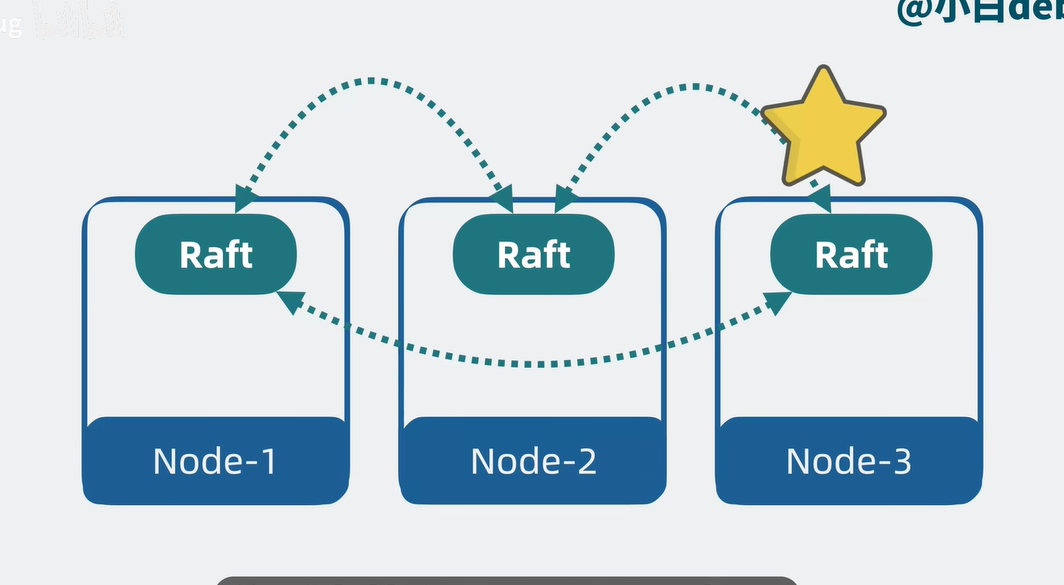
Lucene高可用
- 为了避免node换了,到时分片shard不能服务,保证高可用,添加副本,分词主分片和负分片,主分片会同步到副分片,副本分片不仅能够提供读操作也能够保证主分片挂了时候顶上
node分化
- 为了避免某个集群压力过大,若是每个node都需要集群管理,存储数据,和处理请求的功能,这会导致node的压力还是会变大。所以会进行角色分化的一个操作,每一个node负责不一样的功能。
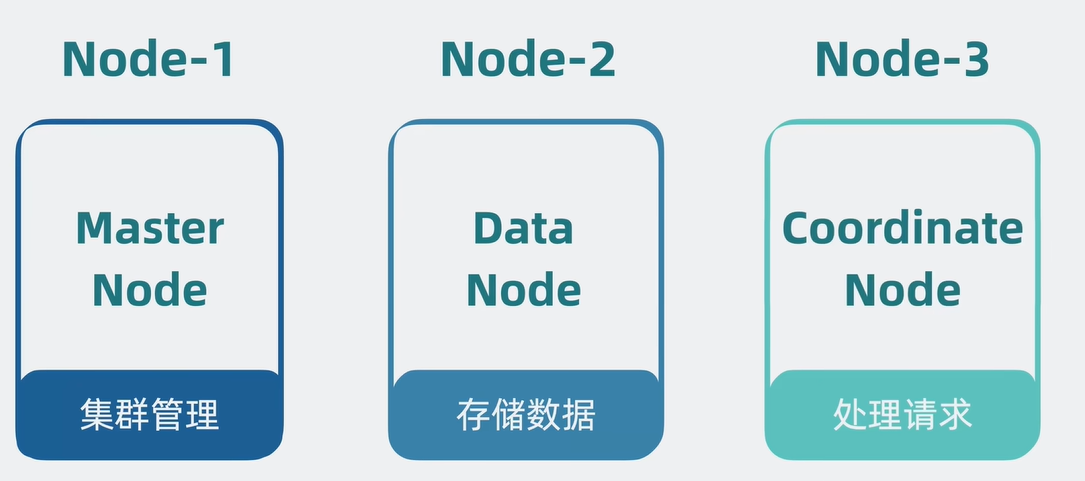
去中心化
总图 这就是ES
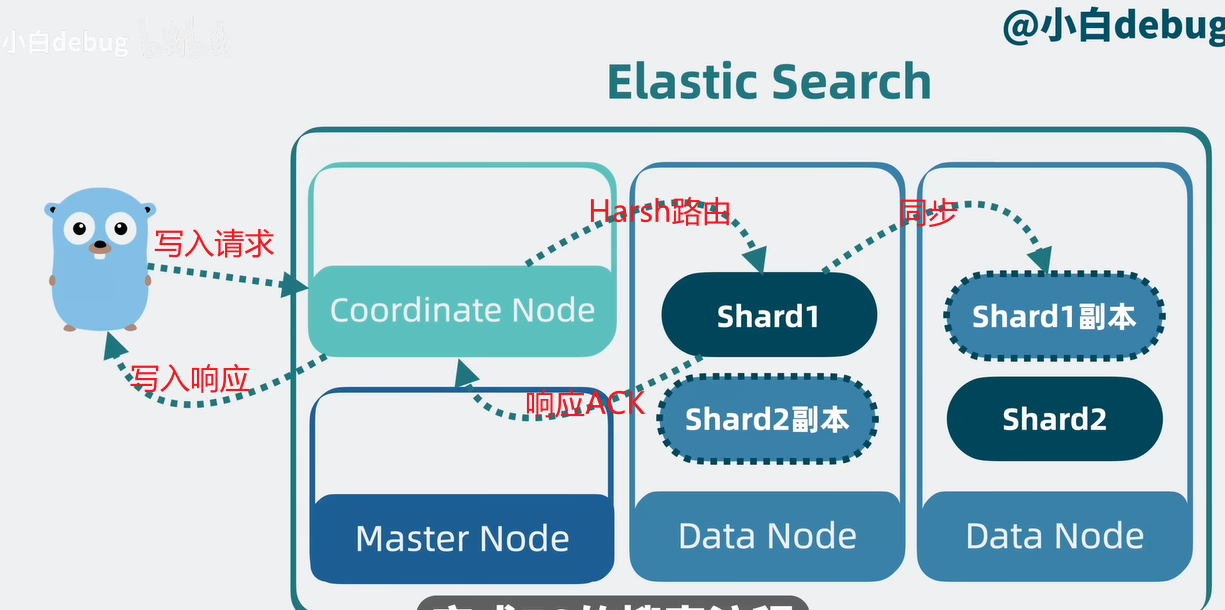
写入流程
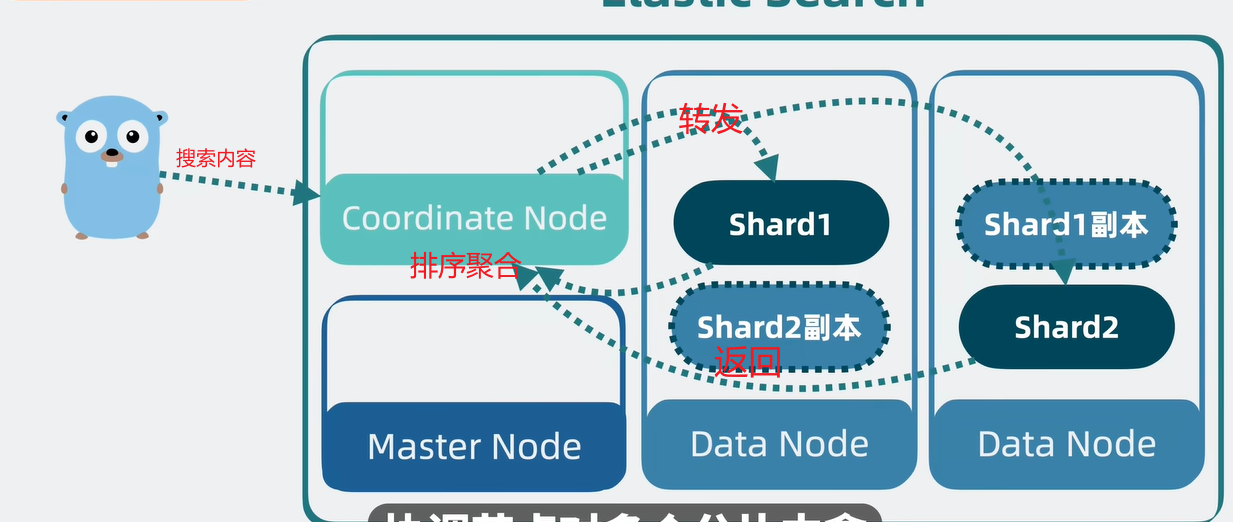
搜索流程
查询阶段
搜索内容:跳过。
转发:是通过index name了解信息在哪个分片和哪个node上面,让后Lucene会并发搜索segment来获取倒排索引的文档id和docvalues获取排序信息。
返回:聚合返回协调节点,然后排序聚合。
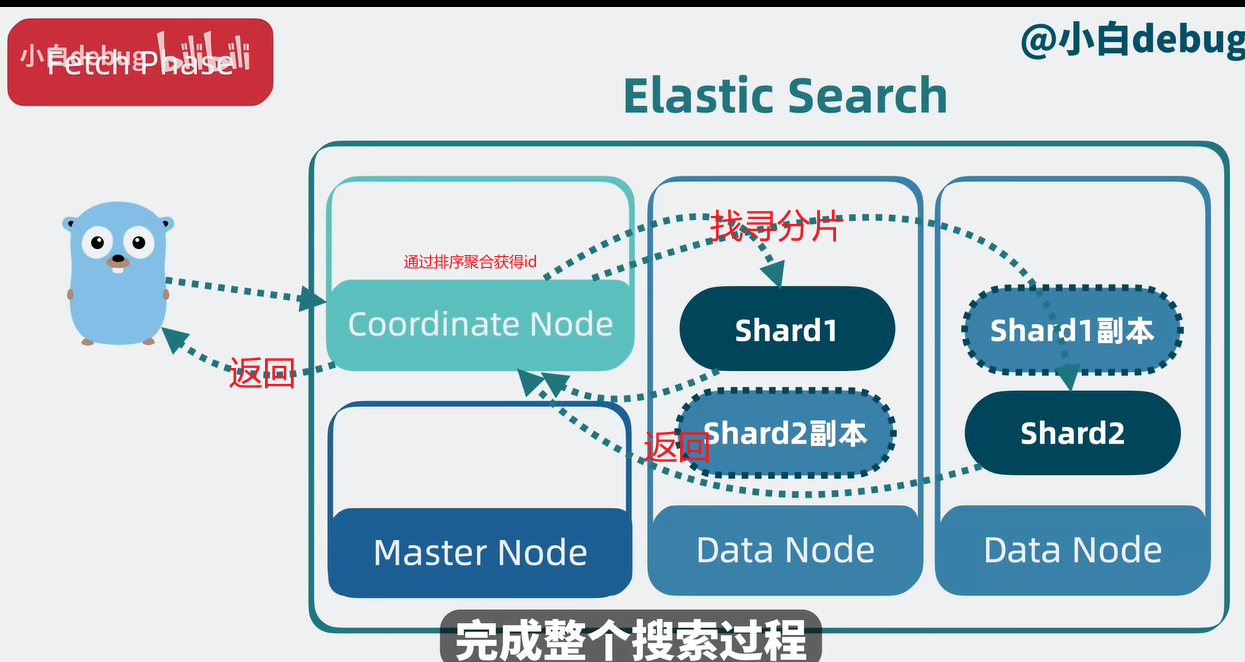
获取阶段
找寻分片:通过文档id,在Stored Fields获取完整文档,然后返回给协调节点,然后返回给客户。
本部落格所有文章除特別聲明外,均採用 CC BY-NC-SA 4.0 許可協議。轉載請註明來自 Kalyan的小书房!
評論
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)