环境准备 节点资源规划(仅学习) 资源规划:一个master,两个work(非测试不建议这种模式,无高可用)
选择安装工具
首先DNS更正223.5.5.5,223.6.6.6
选择后国内清华源的K8s软件库:
选择containerd运行时
安装ipvs
个人理解:环境主要在三节点上有kubelet,kubectl,主节点多一个初始化的kubeadm。然后主节点用kubeadm进行初始化主节点,然后进行containerd运行时进行组件的拉取和运行。组成一个集群。
设置 各种安装过程我们跳过哈,然后我们深度聊一聊一些环境的设置
环境设置 内核参数调整 什么是内核参数呢,会影响什么 内核参数是配置Linux内核行为的设置。这些参数控制系统的各种功能,如内存管理、网络设置、文件系统行为等。内核参数通常通过/etc/sysctl.conf文件进行配置,并通过sysctl命令加载和应用。常用的内核参数请看Linux从核心到边缘 | Kalyan的小书房 (zitiu.top)
需要调整的内核参数 vm.swappiness = 0 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-iptables=1 net.ipv4.ip_forward=1
这里通常会有一个问题,当你sysctl -p采用的时候可能会报错
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
这个时候你可以
sudo modprobe br_netfilter echo 1 | sudo tee /proc/sys/net/bridge/bridge-nf-call-iptablesecho "net.bridge.bridge-nf-call-iptables=1" | sudo tee -a /etc/sysctl.confsudo sysctl -p echo 1 | sudo tee /proc/sys/net/ipv4/ip_forwardecho "net.ipv4.ip_forward=1" | sudo tee -a /etc/sysctl.confsudo sysctl -p
最后进行微调
tee /etc/modules-load.d/k8s.conf <<'EOF' br_netfilter overlay ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack EOF
mkdir -vp /etc/modules.d/cat > /etc/modules.d/k8s.modules <<EOF #!/bin/bash # 允许 iptables 检查桥接流量 modprobe -- br_netfilter # containerd 文件系统支持 modprobe -- overlay # IPVS 模块,用于负载均衡 modprobe -- ip_vs # 轮叫调度算法 modprobe -- ip_vs_rr # 加权轮叫调度算法 modprobe -- ip_vs_wrr # 源地址散列调度算法 modprobe -- ip_vs_sh # 连接跟踪模块,用于跟踪网络连接状态 modprobe -- nf_conntrack EOF
chmod 755 /etc/modules.d/k8s.modulesbash /etc/modules.d/k8s.modules lsmod | grep -e ip_vs -e nf_conntrack
什么是swap分区,为什么要删除.
你可以把swap分区简单理解成是为了分担RAM的负担的这么一个作用,你可以想象一下你有一个书桌,你工作的时候,为了快速获取资料,你会在书桌上堆满书本,这个时候swap就像书架一样,在书架取书会有点慢,但是你起码有位置放书.
那么为什么我们要在kubernetes中要删除呢,继续刚刚的比喻,现在一个研究馆内,有很多书桌(节点),管理人员(k8s调度器)会根据每个人的书桌的容量进行任务的合理分配.如果启动了书架(swap),管理人员可能不知道,你书桌上的实际容量,要是书桌(RAM)把大量资源放到了书架(swap)上,管理人员(调度器)看你的书桌(RAM)空闲,把大量的资源工作丢给你,可能会导致书桌(RAM)的坍塌
一句话:k8s调度器无法知道swap分区里面的情况.
防火墙 这个就不说了,主要是为了更好的后续node以及pod会有自己的网络体系,为了适配关掉最好.
ufw disable && systemctl disable ufw swapoff -a && sed -i 's|^/swap.img|#/swap.ing|g' /etc/fstab
加入清华源后安装系列工具 apt install containerd -y systemctl daemon-reload systemctl enable containerd systemctl restart containerd
containerd设置-配置runtime-endpoint crictl config runtime-endpoint /run/containerd/containerd.sock
要是出现无法连接的情况就检查三个地方
mkdir -vp /etc/containerd/containerd config default > /etc/containerd/config.toml sed -i "s#k8s.gcr.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g" /etc/containerd/config.toml sed -i '/containerd.runtimes.runc.options/a\ \ \ \ \ \ \ \ \ \ \ \ SystemdCgroup = true' /etc/containerd/config.toml CONFIG_FILE="/etc/containerd/config.toml" ; grep -q 'SystemdCgroup' "$CONFIG_FILE " && sed -i 's/SystemdCgroup =.*/SystemdCgroup = true/' "$CONFIG_FILE " || sed -i '/containerd.runtimes.runc.options/a\ \ \ \ \ \ \ \ \ \ \ \ SystemdCgroup = true' "$CONFIG_FILE " sed -i "s#https://registry-1.docker.io#https://xlx9erfu.mirror.aliyuncs.com#g" /etc/containerd/config.toml runtime-endpoint: "unix:///run/containerd/containerd.sock" image-endpoint: "" timeout : 0debug: false pull-image-on-create: false disable-pull-on-run: false
验证containerd的情况 crictl info crictl ps -a | grep kube | grep -v pause crictl logs CONTAINERID
初始化主节点 kubeadm config print init-defaults > kubeadm.yaml kubeadm init --config=kubeadm.yaml --v=5 kubeadm config images list crictl pull
ps:一定要仔细配置kubeadm。
要是containerd有问题的话,修改过config.toml,记得restart一下然后记得
kubeadm reset -f --cri-socket unix:///run/containerd/containerd.sock
ps:修改镜像源后记得修改一下containerd里面的pause的镜像源。
给个样板在这里:
apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups : - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 10.70.49.131 bindPort: 6443 nodeRegistration: criSocket: unix:///run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: masternode-1 taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: type : CoreDNS imageRepository: k8s.m.daocloud.io/coredns imageTag: v1.10.1 etcd: local : dataDir: /var/lib/etcd imageRepository: k8s.m.daocloud.io kind: ClusterConfiguration kubernetesVersion: 1.28.0 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 podSubnet: 10.244.0.0/16 scheduler: {} --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd
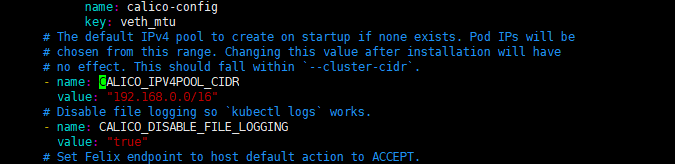
calico wget https://docs.projectcalico.org/v3.18/manifests/calico.yaml
然后自己配置一下
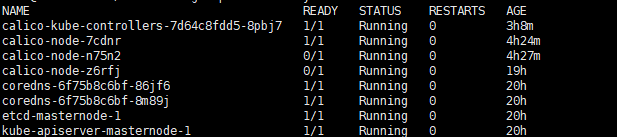
然后apply一下。等待跑起来
哪个拉不起来就去对应的controlby,或者直接deploy上修改image。然后正常来说的话就基本node全部ready


.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)