
排错杂记(pod error)
尝试排错
起因是拉起某个pod的时候持续不断的错误边拉边寄,显示的不是image问题。
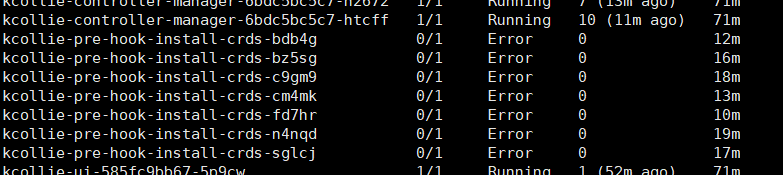
尝试describe一下,发现调度,拉取,创建,启动似乎都正常

这个时候就得去看日志kubectl log一下,

???timeout???kubectl 正常能get不至于访问不到api,api是包正常的。

那就是网络问题,先看一下插件,插件也正常。

再看DNS,似乎有点问题,丢了master3的conredns???

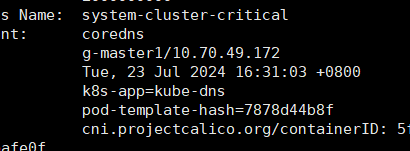
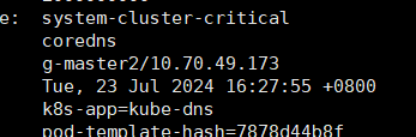
但是查询后这个pod的是属于master1的pod所以不是dns的问题,缺一个的问题后面再解决。
按着尝试手动再吃连接api服务器,草pod fail了,所以用不了,先标记
kubectl exec -it kcollie-pre-hook-install-crds-bdb4g -n kcollie-system -- /bin/sh |
再check一下kube-system的pod
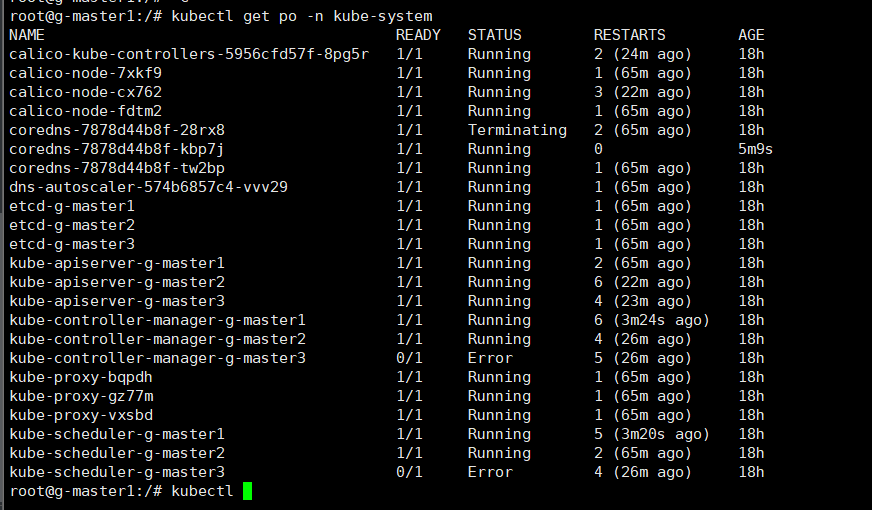
md草了,有屎啊,节点二怎么就timeout了,相继的节点一三也爆屎了。



看一下节点情况,感觉可以rollout整个kube-system,完蛋,怎么查个pod状态,查到整个kube崩了
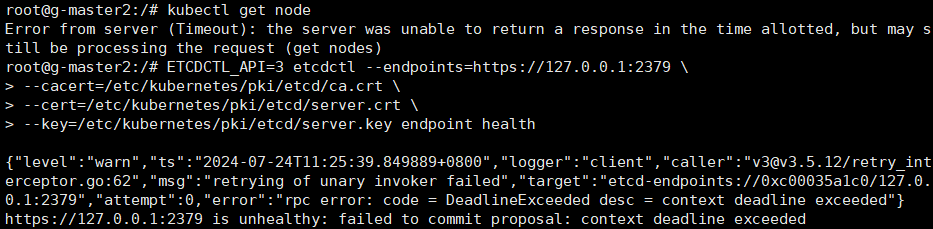
直接rollout所有
# 重启所有 Deployments |
总算是起来了,然后有一个node还是not ready,估计是node3的某些pod还没好,但是报错还是
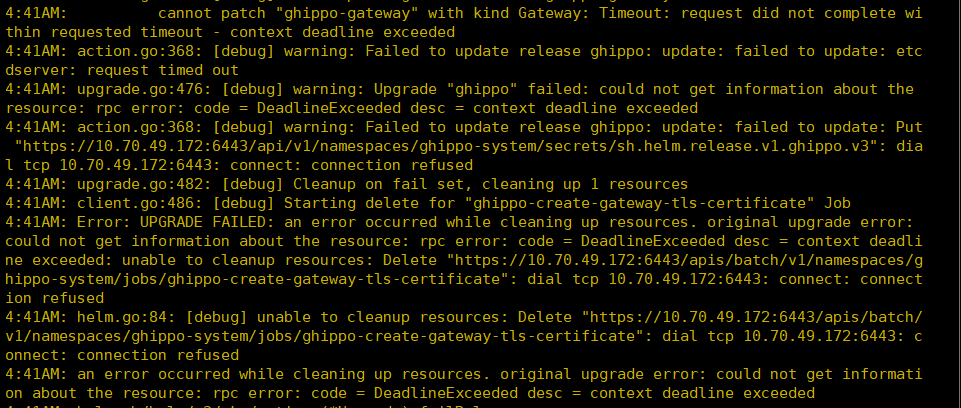
不懂,node1的apiserver明明好好的,coredns也没问题。
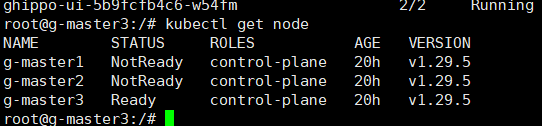
又死了,草啊啊啊啊啊啊啊啊啊啊。节点不知道为什么十分的不稳定,似乎不断崩溃重启,直接停机加内存。
估计上面的Error是不怎么影响的。。。。。。。。重启然后就没事了。
本部落格所有文章除特別聲明外,均採用 CC BY-NC-SA 4.0 許可協議。轉載請註明來自 Kalyan的小书房!
評論
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)